Amazon Web Service’s has come up with many new services and features in recently held AWS re:Invent 2016. In this blog post I am writing about new announcements related to storage and data migration .
AWS Snowmobile:
AWS snowmobile is nothing but a beast to carry petabytes of your data to AWS cloud over a truck. yes on a truck, I am not kidding 🙂

This secure data truck stores up to 100 PB of data and can help you to move exabytes to AWS in a matter of weeks. Snow mobile attaches to you data center network and
appears as local NFS mount volume. It includes a network cable connected to a high-speed switch capable of supporting 1 Tb/sec of data transfer spread across
multiple 40 Gb/sec connections. As per AWS official blogs Snowmobile is available in all AWS Regions. We need to contact AWS Sales team to use this service.
AWS Snowball Edge:
The new Snowball Edge appliance has all the features of its twin brother Snowball which is launched in 2015.

AWS Snowball Edge is Petabyte-scale data transport with on-board storage and compute. It arrives with your S3 buckets, Lambda code, and clustering configuration pre- installed. you can execute AWS Lambda functions and process data locally on the AWS Snowball Edge.You can order Snowball Edge with just a few clicks in the AWS Management Console.
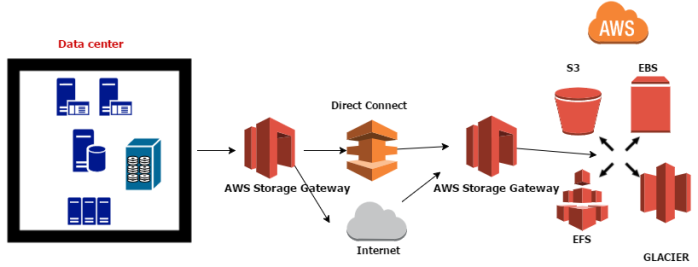
Amazon EFS – New Feature
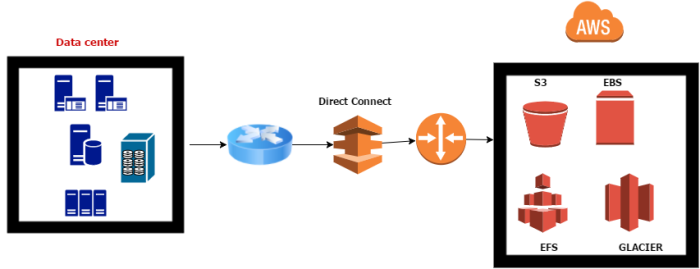
Amazon Elastic File System (Amazon EFS) provides simple file storage for use with Amazon EC2 instances in the AWS Cloud. With new feature we can mount Amazon EFS file systems on our on-premises datacenter servers when connected to Amazon VPC with AWS Direct Connect.
S3 Storage Management with new features
S3 Object Tagging:
S3 Object tags are key-value pairs applied to S3 objects which can be created, updated or deleted at any time during the lifetime of the object.With
these users have the ability to create IAM policies, setup Lifecycle policies, and customize storage metrics.
S3 Analytics, Storage Class Analysis:
This new S3 Analytics feature automatically identifies the optimal lifecycle policy to move less frequently accessed storage to S3 Standard – Infrequent Access .Users
can configure a storage class analysis policy to monitor an entire bucket, a prefix, or object tag. Once an infrequent access pattern is observed, we can easily create
a new lifecycle age policy based on the results.
S3 CloudWatch Metrics :
This helps understand and improve the performance of applications that use Amazon S3 by monitoring and alarming on 13 new S3 CloudWatch Metrics. Users can receive 1-minute CloudWatch Metrics, set alarms, and access dashboards to view real-time operations and performance such as bytes downloaded from their Amazon S3 storage.
you can read my blog post related to Data migration to AWS by clicking below link.Thanks and happy reading 🙂

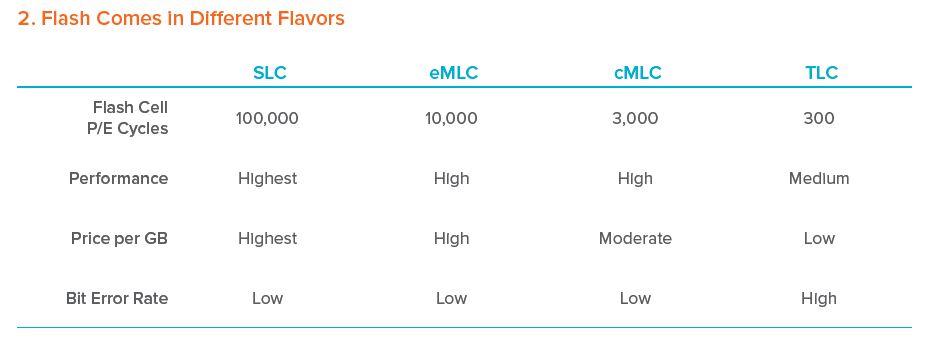
 What is NVMe?
What is NVMe?